文 | 心缘
智东西5月14日报道,刚刚,NVIDIA(英伟达)年度黑科技秀GTC 2020大会通过在线视频的方式举办,被粉丝们亲切称呼为老黄的NVIDIA创始人兼CEO黄仁勋发表主题演讲。
只不过这回演讲的背景不再是科技感十足的大屏幕,而是变成了颇有亲切感的厨房。

此次老黄密集抛出20项重磅新消息,从一个全新GPU架构开始,到全新GPU、全新AI系统、全新AI集群、全新边缘AI产品……每个新品的性能都非常凶残,每秒千万亿次浮点运算(PFLOPS)单位被反复提及!
上一次NVIDIA发布“地表最强AI芯片”Tesla V100还是在2017年,尽管过去三年不断有对手放话称性能超越V100,迄今V100仍是最频繁出现在各家云端AI芯片PPT上的公认性能标杆。
而今天推出的一系列AI产品,是NVIDIA憋了三年的超级核弹!千呼万唤始出来的安培架构、最大7nm芯片、最先进的Mellanox网络技术、进化的特定软件平台……NVIDIA狂出一套组合拳,秀出NVIDIA迄今为止最大的性能飞跃。
遗憾的是,由于疫情的原因,这次GTC大会“老黄”得不到现场观众热情的欢呼捧场了。

接下来闲话不多说,让我们来看看老黄释放了哪些重磅干货:
1、发布第8代GPU架构——安培GPU架构。
2、发布首款基于安培架构的7nm GPU——NVIDIA A100 GPU,包含超过540亿个晶体管,AI训练峰值算力312TFLOPS,AI推理峰值算力1248TOPS,均较上一代Volta架构GPU提升20倍。
3、发布全球最强AI和HPC服务器平台HGX A100,最大可组成AI算力达10PFLOPS的超大型8-GPU服务器。
4、发布全球最先进的AI系统——NVIDIA DGX A100系统,单节点AI算力达到创纪录的5 PFLOPS,5个DGX A100系统组成的一个机架,算力可媲美一个AI数据中心。
5、发布由140个DGX A100系统组成的DGX SuperPOD集群,AI算力最高可达700 PFLOPS。
6、发布新DGX SuperPOD参考架构,帮助客户自身建立基于A100的数据中心。
7、宣布业界首个为25G优化的安全智能网卡(SmartNIC)。
8、发布首款基于NVIDIA安培架构的边缘AI产品——大型商用现货服务器EGX A100。
9、发布世界上最小的用于微型边缘服务器和边缘AIoT盒的最强AI超级计算机——EGX Jetson Xavier NX。
10、发布Jetson Xavier NX开发者工具包,包含云原生支持,该支持可扩展到整个Jetson自主机器的边缘计算产品线。
11、与开源社区合作加速数据分析平台Apache Spark 3.0,可将训练性能提高7倍。
12、NVIDIA Jarvis提供多模态会话AI服务,简化了定制版会话AI服务的构建。
13、发布用于深度推荐系统的应用框架NVIDIA Merlin。
14、展示NVIDIA Clara医疗平台的突破性成就和生态扩展,帮医疗研究人员更快应对疫情。
15、开放式协作设计平台NVIDIA Omniverse现已可供AEC市场的早期体验客户使用。
16、联手宝马,基于NVIDIA Isaac机器人平台打造提高汽车工厂物流效率的物流机器人。
17、小鹏汽车新款P7智能电动汽车及下一代生产车型中拟使用NVIDIA DRIVE AGX平台。
18、小马智行将在其自动驾驶Robotaxi车队中使用NVIDIA DRIVE AGX Pegasus平台。
19、Canoo选择在下一代电动汽车中部署NVIDIA DRIVE AGX Xavier平台。
20、法拉第未来将在其旗舰超豪华FF 91电动车上部署NVIDIA DRIVE AGX Xavier平台。
下面来看这20处新讯具体有哪些亮点。
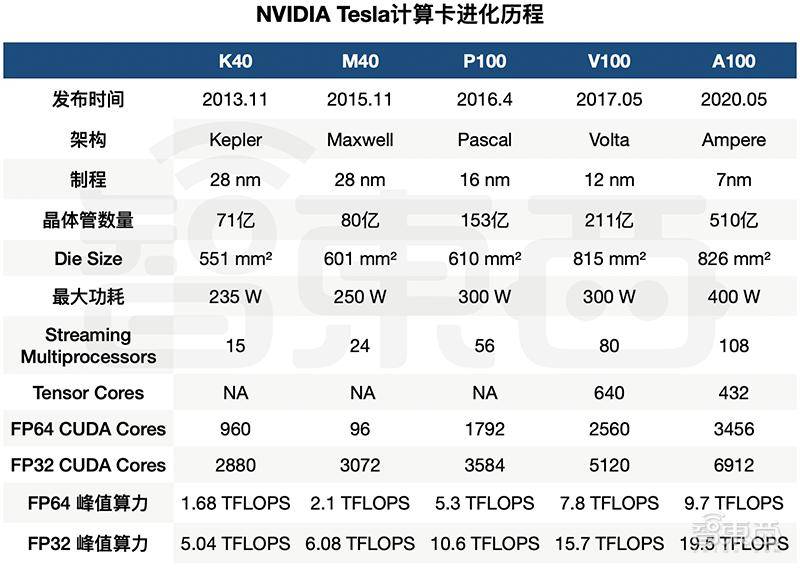
▲NVIDIA计算卡进化历程
一、安培新卡:一统训练、推理和数据分析!
NVIDIA基于安培(Ampere)架构的新一代数据中心GPU——NVIDIA A100 GPU是一个通用的工作负载加速器,也为数据分析、科学计算和云图形而设计,正在全面投产并向全球客户发货。
A100利用了英伟达安培架构的设计突破——成为首个内置弹性计算技术的多实例GPU,提供了NVIDIA迄今为止最大的性能飞跃——统一了数据分析、训练和推理,将AI训练和推理性能提高到上一代的20倍,将HPC性能提升到上一代的2.5倍。

▲NVIDIA A100 GPU
黄仁勋介绍说,这是第一次能在一个平台上实现加速工作负载的横向扩展(scale out)和纵向扩展(scale up)。“NVIDIA A100将同时提高吞吐量和降低数据中心的成本。”
1、A100的五大技术突破
(1)安培架构:A100的核心是英伟达安培GPU架构,面积为826mm²,包含540亿个晶体管,是世界上最大的7nm处理器。
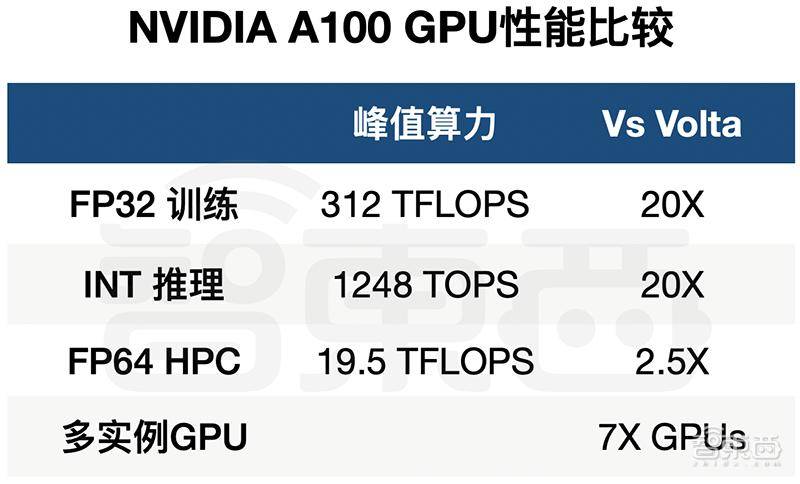
▲NVIDIA A100的训练、推理和数据分析性能比较
(2)第三代张量核心与TF32:NVIDIA第三代张量核心(Tensor Core)更加灵活、更快、更容易使用。其扩展功能包括面向AI的新数学格式TF32,无任何代码更改,可将单精度浮点计算峰值提升至上一代的20倍。此外,张量核现已支持FP64,为HPC应用提供了比上一代多2.5倍的算力。
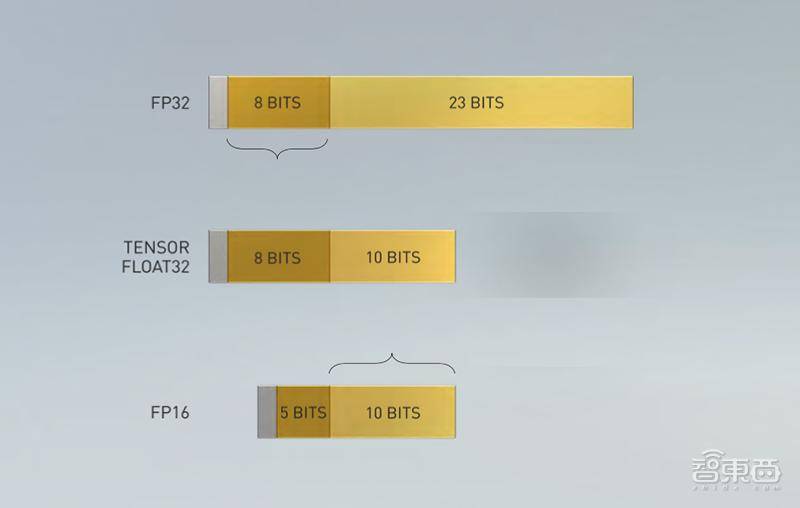
▲TF32拥有与FP32相同的8个指数位(范围)、与FP16相同的10个尾数位(精度)
(3)多实例GPU(MIG):可以将一个A100 GPU分割成多达7个独立的GPU实例,从而为不同大小的任务提供不同程度的计算,提高利用率和投资回报。
(4)第三代NVIDIA NVLink互联技术:使GPU之间的高速连接加倍,可将多个A100 GPU连成一个巨型GPU来运行,从而在服务器上提供高效的性能扩展。GPU到GPU的带宽为600GB/s。
(5)结构稀疏性:这种新的效率技术利用了AI数学固有的稀疏性, 对稀疏AI张量Ops进行优化,将性能提高了一倍,支持TF32、FP16、BFLOAT16、INT8和INT4。
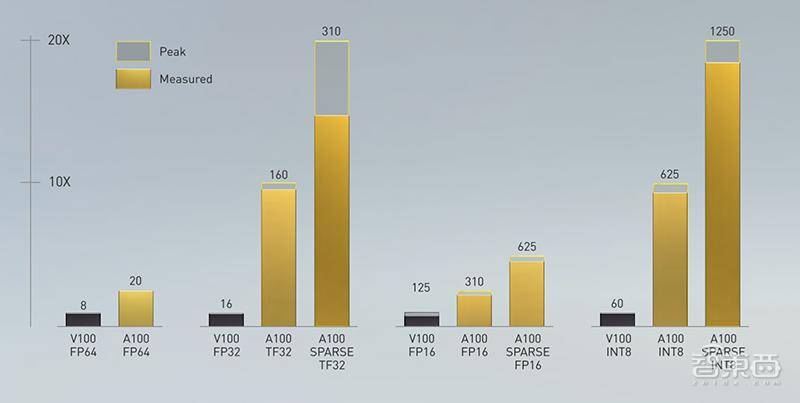
这些新特性一组合,NVIDIA A100就化身多面手,无论是会话AI、推荐系统等AI训练与推理,还是地震建模、科学模拟等数据分析,A100都将是高要求工作负载的理想选择。
例如在运行谷歌自然语言处理模型BERT时,A100将训练性能提升至上一代V100的6倍,推理性能提升至V100的7倍。
2、软件堆栈更新,落地正进行时
硬件升级,软件堆栈也随之更新。
NVIDIA宣布的软件更新内容包括:50多个用于加速图形、模拟和人工智能的CUDA-X库的新版本,CUDA 11,多模态会话AI服务框架Jarvis,深度推荐应用框架Merlin,还有能帮助HPC开发人员调试和优化A100代码的NVIDIA HPC SDK。
A100正被多家世界领先的厂商整合到产品或服务中。其中既包括亚马逊AWS、微软Azure、阿里云、百度云、谷歌云、甲骨文等云服务提供商,也包括Atos、思科、戴尔、富士通、技嘉科技、H3C、惠普、浪潮、联想、微软Azure、广达/QCT、超微等全球领先的系统制造商。
美国印第安纳大学、德国卡尔斯鲁厄理工学院、德国马克斯·普朗克计算和数据中心等高校和研究机构也是A100的早期采用者。
3、HGX A100服务器构建块:加速服务器开发
为了帮助加速来自合作伙伴的服务器开发,NVIDIA打造了超大型数据中心加速器HGX A100——一个以多GPU配置的集成底板形式出现的服务器构建块。

▲NVIDIA HGX A100
4-GPU HGX A100提供了GPU与NVLink之间的完全互联,而8-GPU配置通过NVSwitch提供了GPU到GPU的全带宽。
HGX A100采用了新的多实例GPU架构,可配置为56个小型GPU,每个GPU都比NVIDIA T4快,最大可组成一个拥有AI算力达10 PFLOPS的巨型8-GPU服务器。
二、全球最先进 AI 系统:一个机架比肩整个AI数据中心
老黄亮出的第二个大招,是全球最先进的AI系统——NVIDIA第三代AI系统DGX A100系统,它被称之为“推进AI的终极工具”。

▲NVIDIA DGX A100系统
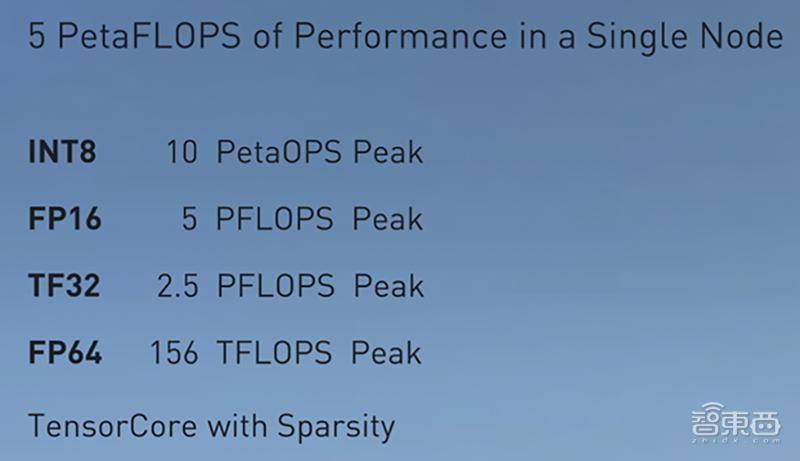
1、单节点AI算力达5PFLOPS
NVIDIA DGX A100系统将训练、推理、数据分析统一于一个平台,这是世界上第一台单节点AI算力达到5 PFLOPS的服务器,首次在一个单一、灵活的平台上提供整个数据中心的功率和性能。
每个DGX A100系统内部集成了8个NVIDIA A100 GPU和320GB内存。借助A100多实例GPU特性,每个系统可配置1到56个独立的GPU实例,从而交付灵活的、软件定义的数据中心基础设施。
现场老黄算了一笔账,一个典型的AI数据中心有50个DGX-1系统用于AI训练,600个CPU系统用于AI推理,需用25个机架,消耗630kW功率,成本逾1100万美元。
而完成同样的工作,一个由5个DGX A100系统组成的机架,达到相同的性能要求,只用1个机架,消耗28kW功率,花费约100万美元。
这样一算,正应了老黄那句名言“买的越多,省的越多”,DGX A100系统用一个机架,就能以1/10的成本、1/20的功率、1/25的空间取代一整个AI数据中心。
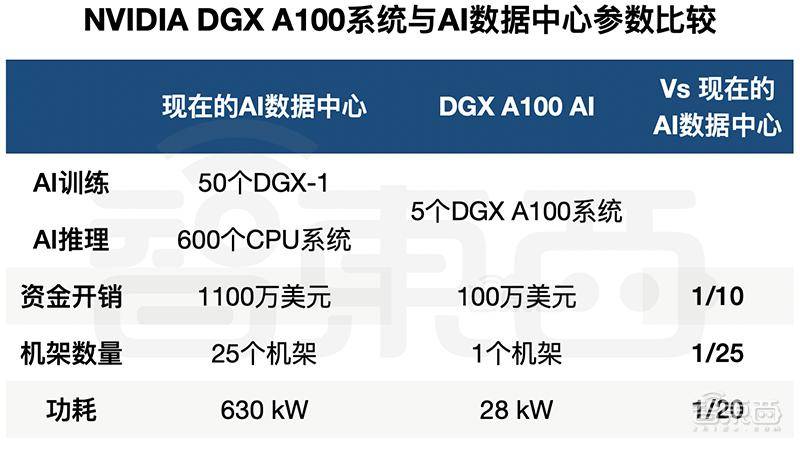
▲NVIDIA DGX A100系统与AI数据中心参数比较
DGX A100系统由NVIDIA DGX软件栈提供支持,其中包括针对AI和数据科学工作负载的优化软件,支持加速Spark 3.0、RAPIDS、Triton、TensorFlow、PyTorch等,使企业在AI基础设施上的投资获得更快的回报。
结合这些功能,企业可以在一个完全集成的、软件定义的平台上优化算力和按需资源,以加速数据分析、训练和推理等不同工作负载。
2、首批系统已交付,用于抗击新冠肺炎
DGX A100系统起价19.9万美元,已经开始在全球范围内交付,现可从NVIDIA及其已认证的合作伙伴处获取。
第一批DGX A100系统于本月早些时候交付给美国阿贡国家实验室(Argonne National Laboratory),用于加速COVID-19研究。

▲安装在阿贡国家实验室的NVIDIA DGX A100系统
“新型DGX A100系统的计算能力,将帮助研究人员探索治疗方法和疫苗,并研究病毒的传播,使科学家能够在数月或数天内完成此前需要花费多年的AI加速工作。”阿贡计算机、环境和生命科学实验室副主任Rick Stevens说。
此外,多家全球大公司、服务提供商和政府机构已为DGX A100下了初始订单。

例如存储技术供应商DDN存储、戴尔、IBM、NetApp、Pure Storage和Vast均计划将DGX A100集成到他们的产品中,包括基于NVIDIA DGX POD和DGX SuperPOD参考架构的产品。
3、最快AI超算登场!AI算力达700PFLOPS
老黄还发布了新一代DGX SuperPOD集群,它由140个DGX A100系统与NVIDIA Mellanox200Gbps InfiniBand互连技术提供动力,AI算力达700 PFLOPS,实现了以前需要数千台服务器才能达到的性能水平,相当于世界上最快的20台AI超级计算机之一。

▲NVIDIA DGX SuperPOD
DGX A100的企业就绪型架构和性能,使得NVIDIA只用一个月就可以构建系统,而不是像以前那样需要数月或数年的时间来计划和采购专门的组件以交付这些超级计算能力。
NVIDIA也在扩展自己的超算SATURNV。此前SATURNV包含1800个DGX系统,算力最高为1.8 ExaFLOPS。如今NVIDIA在SATURNV新增4个DGX SuperPOD,SATURNV的总算力峰值增至4.6 ExaFLOPS。
为了帮助客户自身建立基于A100的数据中心,NVIDIA发布了一个新的DGX SuperPOD参考架构。它为客户提供了一份蓝图,该蓝图遵循英伟达用于构建基于DGX A100的AI超级计算集群的设计原则和最佳实践。
4、服务到家!专家指导,软件就绪
NVIDIA还推出了NVIDIA DGXpert计划,将DGX客户与公司的AI专家聚集在一起。
DGXpert是精通AI的专家,可以帮助指导客户进行从计划到实现再到持续优化的AI部署,可帮助DGX A100客户建立和维护最先进的AI基础设施。
NVIDIA DGX-ready软件程序帮助DGX客户快速识别并利用NVIDIA测试的第三方MLOps软件,帮助他们提高数据科学生产力,加速AI工作流程,并改善可访问性和AI基础设施的利用性。
NVIDIA认证的第一个项目合作伙伴是Allegro AI、cnvrg.io、Core Scientific、Domino Data Lab、Iguazio和Paperspace。
三、业界首个为 25Gb/s 优化的安全智能网卡
NVIDIA还发布了一款安全高效的以太网智能网卡Mellanox ConnectX-6 Lx SmartNIC,它是业界首个为25Gb/s优化的安全智能网卡,用于加速云计算和企业工作负载。
ConnectX-6 Lx是ConnectX家族的第11代产品,目前正在进行采样,预计将在2020年第三季度实现全面可用。

▲NVIDIA Mellanox ConnectX 6 Lx智能网卡
新SmartNIC通过利用软件定义、硬件加速的引擎来扩展加速计算,从CPU上卸载更多的安全和网络处理。
25Gb/s的连接正在成为处理企业应用程序、AI和实时分析等高要求工作流的标准。此次发布的Mellanox ConnectX-6 Lx智能网卡可提供两个25Gb/s端口或一个50Gb/s端口,其以太网与PCIe Gen 3.0/4.0 x8主机连接。
ConnectX-6具备IPsec内置加密加速、信任硬件根等加速安全特性,以及10倍的连接跟踪性能改进,使整个数据中心实现零信任安全。
该智能网卡还支持GPUDirect RDMA加速跨网络传输NVMe(NVMe-of)存储,进而横向扩展加速计算和高速视频传输应用;并具备Zero Touch RoCE(ZTR)技术,无需配置开关即可获得一流的RoCE,进而实现可扩展、易于部署的网络特性。
除了上述功能外,ConnectX-6也通过内置虚拟化和容器化的SR-IOV和VirtIO硬件卸载,提供加速交换和包处理(ASAP2),用于加速下一代防火墙服务的软件定义网络和连接跟踪。
与ConnectX家族的所有产品相同,Mellanox ConnectX-6 Lx与Mellanox SmartNIC软件兼容。与Mellanox Spectrum开关和LinkX系列电缆和收发器一起,ConnectX SmartNIC为高性能网络提供了最全面的端到端解决方案。
四、 EGX 边缘 AI 平台:将实时 AI 带入传统行业
老黄还宣布两款强大的EGX Edge AI平台产品——大型商用现货服务器EGX A100和微型边缘服务器EGX Jetson Xavier NX,将强大的实时云计算能力带到边缘。
黄仁勋认为,物联网(IoT)和AI的融合开启了“智能一切”革命,NVIDIA EGX边缘AI平台将标准服务器转变为一个小型云原生的、安全的AI数据中心,基于其AI应用框架,公司可以构建从智能零售、机器人工厂到自动化呼叫中心的智能服务。
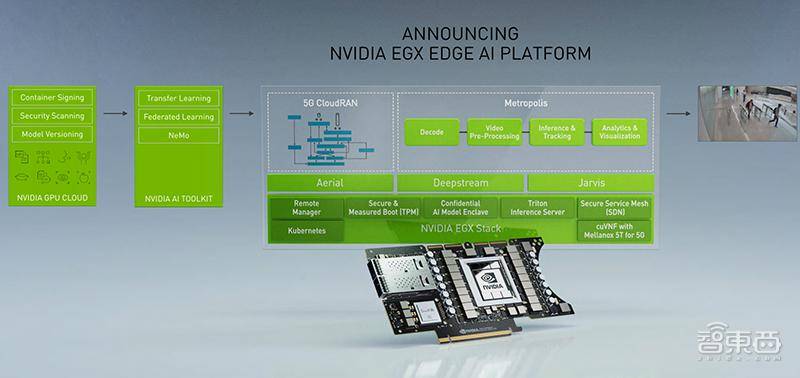
▲NVIDIA EGX边缘AI平台
NVIDIA EGX A100是首款基于NVIDIA安培架构的边缘AI产品,安培架构GPU为其提供了第三代张量核心和新的安全特性,该产品将在今年年底上市。
通过搭载NVIDIA Mellanox ConnectX-6 Dx SmartNIC技术,EGX A100可以接收高达200Gbps的数据,并将其直接发送到GPU内存进行AI或5G信号处理,兼顾安全性和闪电般快速的网络功能。
作为一个云原生的、软件定义的加速器,EGX A100可以处理5G中对延迟最敏感的用例。这为制造、零售、电信、医疗等行业做出智能实时决策提供了高效的AI和5G平台。

▲NVIDIA EGX A100
EGX Jetson Xavier NX是世界上最小、最强大的用于微服务器和边缘AIoT盒子的AI超级计算机。
EGX Jetson Xavier NX将NVIDIA Xavier SoC芯片的强大功能集成到一个信用卡大小的模块中,该模块具有服务器级的性能,15W功耗限制下最多可提供21TOPS的算力,10W功耗限制下最多可提供14TOPS的算力。
通过运行EGX云原生软件栈,EGX Jetson Xavier NX可快速处理来自多个高分辨率传感器的流数据。
这为受到尺寸、重量、功率预算或成本限制的嵌入式边缘计算设备打开了大门,目前已提供给希望创建大容量生产边缘系统的公司,有来自生态系统合作伙伴的20多个解决方案。

▲EGX Jetson Xavier NX微边缘服务器
两款产品为满足不同的大小、成本和性能需求而创建的。比如,EGX A100可管理机场的数百台摄像头,而EGX Jetson Xavier NX的设计目标是管理便利店的少数摄像头。
Jetson Xavier NX开发工具包和Jetson Xavier NX模块现可通过英伟达的分销渠道购买,售价399美元。
在麻省理工学院(MIT)航空航天副教授Sertac Karaman看来,拥有云原生支持的Jetson平台是一项重要的新开发,有助于构建和部署未来几代自主机器。
EGX边缘AI平台的云原生架构允许其运行集装化软件,确保整个EGX系列可以使用相同的优化AI软件,以轻松构建和部署AI应用程序。
NVIDIA的应用框架包括用于医疗的Clara、用于电信5G的Aerial、用于会话AI的Jarvis、用于机器人技术的Isaac,以及用于智能城市、零售、交通等的Metropolis。这些平台可以一起使用,也可以单独使用,为各种边缘用例开辟了新的可能性。
基于云原生支持,智能机器制造商和AI应用程序开发人员可以在针对机器人、智能城市、医疗保健、工业物联网等领域的嵌入式和边缘设备上,构建和部署高质量、软件定义的功能。

现有使用NVIDIA EGX软件的边缘服务器,可从Atos、戴尔、富士通、千兆、惠普、技嘉、IBM、浪潮、联想、广达/QCT和超微等全球企业计算供应商处获得,也可从Advantech和ADLINK等主流服务器和物联网系统制造商处获得。
五、当今世界上最重要的应用,四类软件更新扩展
根据老黄的演讲,NVIDIA GPU将为主要软件应用提供支持,重点加速四大关键应用:管理大数据、创建推荐系统、构建会话AI、进化AI医疗算法。
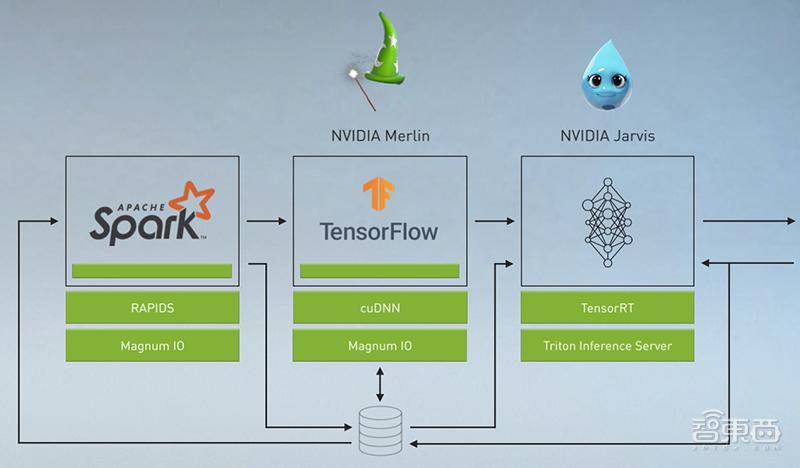
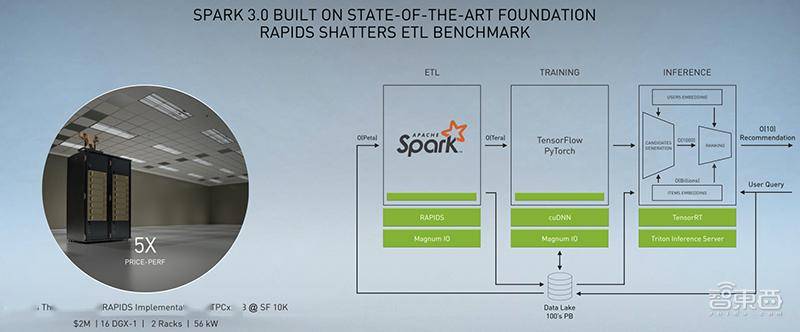
1、加速数据分析平台Apache Spark 3.0
为了帮更多机构赶上机器学习的浪潮,NVIDIA正与开源社区合作,将端到端的GPU加速引入有50多万数据科学家在使用的数据分析平台Apache Spark 3.0。 老黄将该平台描述为“当今世界上最重要的应用之一”。
基于RAPIDS,Spark 3.0突破了提取、转换和加载数据的性能基准,支持跨整个数据科学管道的高性能数据分析,加速了从数据湖到模型训练的数万兆字节的数据,而无需更改运行在本地及云端Spark 应用的现有代码。
▲NVIDIA Spark 3.0
这将是首次把GPU加速应用于使用SQL数据库操作广泛执行的ETL数据处理工作负载,也是AI模型训练第一次能在同一个Spark集群上加速数据准备和模型训练,而不是将工作负载作为单独的进程在单独的基础设施上运行。
Spark 3.0的性能提升,使得每天处理TB级的新数据成为可能,使科学家能用更大的数据集训练模型,并更频繁地重新训练模型,从而提高了模型的准确性,并节约大量成本。
Adobe是首批在Databricks上运行Spark 3.0预览版的公司之一。在最初的测试中,它的训练性能提高了7倍,节省了90%的成本。
此外,老黄还宣布,亚马逊SageMaker、Azure机器学习、Databricks、谷歌云AI和谷歌云Dataproc等关键的云分析平台都将由NVIDIA提供加速。
Spark 3.0预览版现可从Apache Software Foundation获得,预计在未来几个月发布。
2、发布构建推荐系统的端到端框架Merlin
NVIDIA Merlin是一个用于构建下一代推荐系统的端到端框架,它正迅速成为更加个性化的互联网的引擎。
老黄说,Merlin将从100tb数据集创建推荐系统所需的时间从4天缩短到了20分钟。
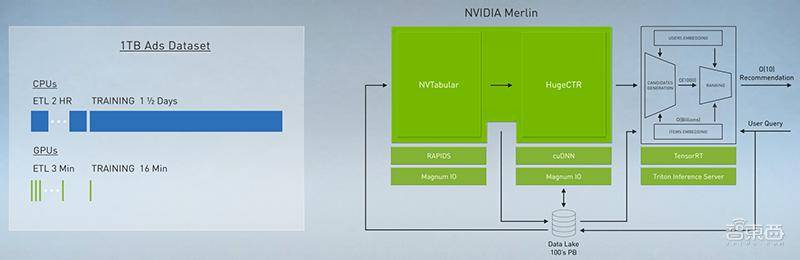
基于深度学习的推荐系统正在推动阿里巴巴、亚马逊、百度等互联网巨头的增长。但要打造持续优化的推荐系统,需要更多查询、更快的速度、在基础设施上投入更多的资金,以跟上不断膨胀的数据量。
而在NVIDIA Merlin推荐应用框架发布后,推荐系统不再是科技巨头的专利,其他人同样能便捷地采集数据、训练和部署GPU加速的推荐系统。
这些系统将可利用最新NVIDIA A100 GPU,比以往更快更经济地构建推荐系统。
3、简化最先进的会话AI构建
NVIDIA Jarvis是一个用于创建实时、多模态会话AI的端到端平台,包含NVIDIA最大的自然语言理解模型Megatron BERT等先进深度学习模型,其应用框架简化了最先进会话AI服务的构建。
在演讲期间,老黄演示了他与一个友好的AI系统Misty的互动,Misty能实时理解并回答一系列复杂的天气问题。
虚拟助手和聊天机器人的发展正推动会话AI市场的快速增长。IDC预计,到2023年,自动客户服务代理和数字助理等AI会话用例的全球支出将从2019年的58亿美元增长到138亿美元,复合年增长率为24%。
Jarvis提供了一个完整的GPU加速的软件堆栈和工具,使开发人员可以轻松地创建、部署和运行端到端实时的定制版会话AI应用。这些应用可以理解每个公司及其客户的独特术语。
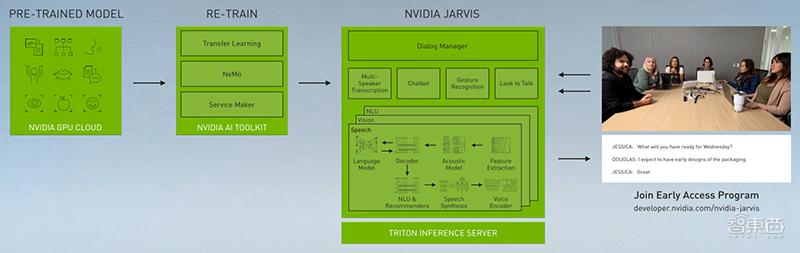
▲NVIDIA Jarvis
使用Jarvis构建的应用程序可以利用新NVIDIA A100 Tensor Core GPU在AI计算方面的创新和NVIDIA TensorRT中用于推理的最新优化。
据悉,这是第一次可以使用最强大的视觉和语音模型来运行整个多模态应用程序,比实时交互所需的300毫秒阈值还要快。
第一批使用基于Jarvis的会话AI产品和服务为客户提供服务的公司包括提供呼叫服务AI虚拟代理的Voca、面向金融和商业的自动语音转录的Kensho,以及用于预约安排的AI虚拟助手Square。
4、NVIDIA Clara医疗平台扩展生态合作伙伴
面向医疗领域,老黄公布NVIDIA Clara医疗平台的最新突破性成就,并宣布扩展其全球医疗合作伙伴,以帮助医学界更好地跟踪、测试和治疗COVID-19。
(1)打破记录的基因组测序速度:NVIDIA Clara Parabricks计算基因组软件,实现了一项新的速度记录,在20分钟内分析整个人类基因组DNA序列,使得研究人员对病人对疾病的易感性、疾病的进展和对治疗的反应有了更深入的了解。
(2)疾病检测AI模型:这是与美国国立卫生研究院(National Institutes of Health)联合开发了一款AI模型,能帮助研究人员通过胸部CT扫描检测和研究COVID-19感染的严重程度,并开发新的工具来更好地理解、测量和检测感染。这些模型可即刻在最新发布的Clara成像技术中获得。
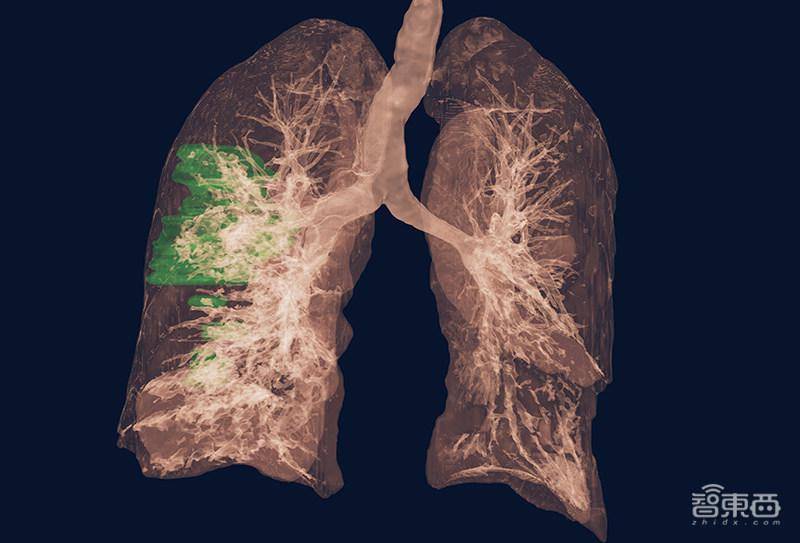
▲基于NVIDIA Clara COVID-19 AI分类模型的肺部影像
(3)医院智能化:NVIDIA Clara Guardian智能医院推出了NVIDIA Clara Guardian智能视频分析和自动语音识别技术,通过将日常传感器转换为智能传感器,提供自动体温检测、面罩检测、安全社交隔离和远程患者监测等关键用例,新一代的智能医院可以执行生命体征监测,同时限制工作人员接触。
整个生态系统的合作伙伴正在使用预训练的模型和迁移学习,来开发和部署融合视觉、语音和自然语言处理的AI应用程序。使用NVIDIA EGX AI Edge平台进行部署,使解决方案供应商能够在整个医院环境中安全地部署和管理大量设备。
该生态系统有数十个解决方案合作伙伴,已在全球超过50家医院和10000间病房部署基于NVIDIA Clara Guardian的解决方案。
5、支持远程设计协作的Omniverse
在今天的主题演讲中,老黄宣布计算机图形和仿真平台NVIDIA Omniverse现已可供AEC市场的早期访问(early access)客户使用。
它是一个开放式设计协作平台,允许不同设计师用不同工具在不同的地方,无缝协作完成同一设计项目的不同部分。
老黄还在演示了Omniverse高光仿真和实时GPU渲染的更新,以及来自不同行业的客户如何使用Omniverse的早期测试版本。
现在购买AEC的RTX服务器配置的客户可以使用Omniverse early access程序,有能力成为Omniverse AEC体验项目的一部分。
六、联手宝马!重新定义工厂物流
NVIDIA也在继续推进其NVIDIA Isaac软件定义的机器人平台,宣布宝马集团已选择NVIDIA Isaac,通过打造基于先进AI计算和可视化技术的物流机器人,提高其汽车工厂物流效率,以更快更有效地生产定制配置的汽车。
一旦开发完成,该系统将部署到宝马集团的全球工厂。
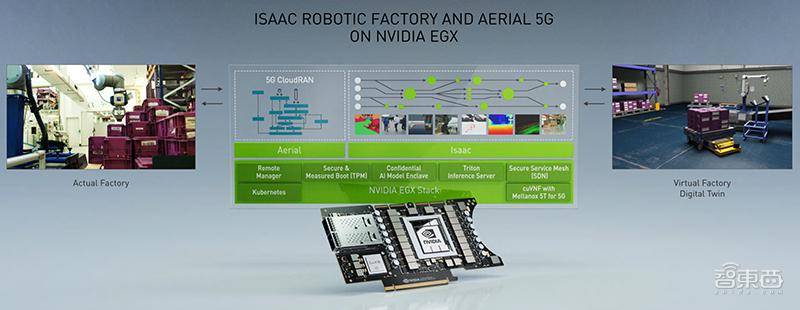
▲基于NVIDIA EGX的Issac机器人工厂和Aerial软件开发工具包
宝马集团在全球的工厂每56秒生产一辆新车,有40种不同的车型,宝马集团的供应链由来自世界各地数千家供应商的数百万个零部件生产而成,涉及23万个零件号,且99%的客户订单彼此之间具有独特的区别。这些给工厂物流带来了巨大的挑战。
为了优化物流,自动AI驱动的物流机器人现在协助当前的生产流程,以便在同一条生产线上组装高度定制的车辆。
NVIDIA Isaac机器人平台包括Isaac SDK、Isaac Sim、AGX和DGX,各组件一起协作来设计、开发、测试、计划和部署宝马制造工厂的物流机器人。
宝马集团借助NVIDIA Isaac机器人平台开发出5个支持AI的机器人,以改进其物流工作流程,其中包括自动运输材料的导航机器人、选择和组织零件的操作机器人。
这些机器人经由真实和合成数据进行训练,使用NVIDIA GPU在各种光线和遮挡条件下渲染光线追踪机器部件,以增强真实数据。然后用真实和合成的数据在NVIDIA DGX系统上训练深度神经网络。
整个过程由高性能NVIDIA Jetson AGX Xavier和EGX边缘计算机提供动力。
在NVIDIA Omniverse平台上,这些机器人将在NVIDIA Isaac模拟器上连续进行导航和操作测试,来自不同地理位置的多名宝马团队人员都可以在一个模拟环境中工作。

▲NVIDIA Isaac平台在宝马工厂同步工作
宝马加入了庞大的NVIDIA机器人全球生态系统,涵盖送货服务、零售、自主移动机器人、农业、服务、物流、制造和医疗。
老黄相信,未来工厂将变成巨大的机器人,每个批量生产的产品都将是定制的。
七、 NVIDIA 的五个自动驾驶新伙伴
老黄说,自动驾驶汽车是我们这个时代面临的最大的计算挑战之一,对此NVIDIA正着力推进NVIDIA DRIVE平台。
NVIDIA DRIVE将使用新的Orin SoC和嵌入式NVIDIA安培GPU,以实现能源效率和性能,为前挡风玻璃提供5瓦的ADAS系统,并将规模扩大到2000TOPS、L5级Robotaxi系统。
根据今天新公布内容,中国电动汽车制造商小鹏汽车新推出的P7智能电动车及下一代生产车型、美国电动汽车新创企业Canoo的下一代电动汽车、法拉利未来的旗舰超豪华FF 91电动车,都计划采用NVIDIA DRIVE AGX Xavier平台。

NVIDIA Xavier是世界上第一个为自动驾驶设计的处理器,可提供30TOPS算力,同时只消耗30W的功率,且满足当今严格的安全标准和监管要求。自动分级的Xavier SoC现已投入生产,基于安全架构,集成了六种不同类型的处理器,用于运行AI、传感器处理、地图绘制和驾驶的不同算法。
由于小鹏汽车与Xavier平台具有很强的架构兼容性,小鹏汽车也在积极探索将NVIDIA Orin平台应用于未来一代智能电动汽车的潜在机会。
NVIDIA Orin是世界上性能最高、最先进的自动车辆和机器人SoC,算力可达200TOPS,同时也能够缩小到入门级ADAS/Level 2用例,功耗低至5W。

▲NVIDIA Orin SoC
此外,中国自动驾驶技术公司小马智行(Pony.AI)也将在其自动驾驶移动出行Robotaxi车队中部署NVIDIA DRIVE AGX Pegasus自动驾驶平台。
DRIVE AGX Pegasus采用安全的架构,算力达320TOPS,集成了2个NVIDIA Xavier SoC和2个NVIDIA图灵张量核心GPU。
下一代NVIDIA Drive Robotaxi解决方案拟集成2个Orin SoC、2个安培GPU,算力提升6倍至2000TOPS,能效提升4倍。
老黄说:“现在汽车制造商可以利用整个车队的软件开发,用一种架构开发整个车队。”
NVIDIA DRIVE生态系统现在包括汽车、卡车、L1级汽车供应商、下一代移动服务商、初创公司、地图服务商等。

此外,老黄还宣布英伟达将把NVIDIA DRIVE RC添加到其驱动技术套件中,用于管理整个车队的自动驾驶车辆。
结语:诚意满载,献礼AI
自AI第三次浪潮爆发以来,NVIDIA始终是其中最为耀眼而又无可替代的明星企业之一。如今的GTC大会,不仅是NVIDIA先进产品和服务的集中秀场,亦是全球AI和深度学习领域举足轻重的一大技术盛事。
尽管疫情所碍,GTC 2020比原计划的3月来的稍晚些,但从今日NVIDIA发布的内容来看,这场围绕AI算力的饕餮盛宴仍令人感到惊喜。时隔三年,NVIDIA不仅带来了新一代安培架构,还一并秀出包括GPU芯片、AI系统、服务器构建块、AI超级计算机、边缘服务器产品、嵌入式AI产品等全套AI计算大礼包,自动驾驶生态也在稳定地持续扩张。
我们可以看到,经过经年累月的积累和打磨,NVIDIA在技术、产品、生态链、供应链等方面的优势都已是难以逾越的高山。
如今AI芯片市场日渐呈现百家争鸣之态势,创新架构风起云涌,云边端都陆续出现新的挑战者。因GPU加速和AI崛起而声名赫赫的NVIDIA,依然在AI赛道上全速向前奔跑,如果不出意外,我们大概很快会在新一轮AI芯片的发布潮中,看见基于安培架构的NVIDIA A100 GPU成为新的性能衡量标杆。
而成为新性能标杆的A100又将给AI和数据科学领域带来怎样的变局?这又将是一个新的令人期待的故事。

















